I’m going to assume you read the title wrong because making money off draft blog posts would just be ridiculous.
When you’re making a post on your Wordpress blog you have three options under the Post Status. You can have your post be Published, which means its live and public, or you can have it as a draft which means you’re still working on it or lastly private meaning only you can view it. Draft posts have their obvious purpose. It allows you to do one of those nasty habits you pick up in college called proof reading. Other than that they really have no significant value. However there is a sneaky way to make some decent reoccurring cash off them. Yes, I’ll be happy to show you how!
First, in an effort to better my posts I’m going to experiment and take a different direction with my explanation of how to do this tactic. I get an abundant supply of people telling me my methods are too hard to follow. Perhaps its my engineering book method of explaining it. I find it easier to learn that way but perhaps it’s not for everyone. I would like them to be; so instead of posting the usual processes and methodologies I’m going to tell you a story.
Once upon a time…
There was a studly Internet marketer named Eli. Eli loved spam blogs. He loved them so much he called them Splogs because he talked about them so much the words kind of meshed into an incomprehensible word that for some reason everyone understood. On this particular gloomy day our lovable hero Eli was making a Splog to test the stickiness of trackback links. Eli knew all about trackback links and how they were useful for notifying other blogs when he posted a link about their individual posts through a link that showed up in their comments. He was also well aware of the fact that most blogs post a special url on each post that you can use to post your trackback links on. With this information in his pocket he was equipped to perform an experiment, an experiment in figuring out a way to increase the percentage of bloggers that would keep his trackback link live in their comments.
This was no ordinary experiment. Danger and wacky misadventures were inevitable. He first tried sending unrelated trackbacks to older posts from abandoned blogs with some success. However he wanted new posts from big time blogs that are updated consistently and he desperately wanted some of their continuous traffic stream. This posed a problem for our young marketer. They would always delete them before they could gain enough link value and throughput traffic sufficient enough for ad profit. A worthy adversary. Thinking on his toes Eli started targeting blog posts that were relevant to his desired ads. He then put up a post saying saying something like:
“I just got this new *product name* today from Circuit City. Its really cool and it got some great reviews. Check out *trackback target 1*, *trackback target 2* ….etc. They post some great insight into the *product name* and what you can do with it.”
He then made sure to include NONE of his own ads. This was very risky but hey he was willing to sacrifice for the sake of knowledge. Luckily success! The big time blogs with continuous traffic saw no reason to remove his trackback links. Eli complimented and linked to their blogs with no ads and motive to do so and they were stoked about it.
Eli was beaming with joy. His Splog was gaining in daily traffic from all the trackback links. the more posts he made about this seemed to draw in more daily traffic from the links. Eli frantically upped his post count hoping to duplicate the success a 100 fold. However much to his dismay the success rate of the trackback links sticking went down. The big bloggers would see all his extremely similar posts and delete his trackback. If he wanted to keep his stickiness success rate he was going to have to delete some posts. This was not a reasonable solution and it made him sad. So instead he took all of his posts over two months old and changed their status to “Draft.” This made them not appear on the actual blog but if you went directly to the urls by following a trackback link they were still there in their entire form. In a stroke of genius he also made a few fake posts that made his Splog look legit and put their post date for the next year and made them so they would always be on the main page of his Splog.
Success! Eli was driving in even more traffic to the individual posts because of the sheer volume he could produce without anyone being the wiser. Once a post became 2 months old he would automatically change it to draft mode. Eli also knew that bloggers only checked their trackback links once or twice for legitimacy before forgetting about them. So after 4 months he started replacing his original posts and their links with affiliate links to the individual products. Eli’s Splog continued to get traffic from the trackbacks and each visitor was greeted with a nice affiliate link VIA a snazzy sales page to where they could buy the product. He made much money and lived happily ever after.
The End
Story time is over kids. Get back to work.
Sorry I haven’t been posting lately guys. I got lots of pretty damn good excuses for it but I’ll spare you of having to hear them. This week I’m back on the ball and I’m going to attempt to up my post volume to make up for the slack the last week and a half.
Today’s post is a detailed way to deal with pesky hotlinkers. Hotlinkers are people who use your binary content and instead of hosting it themselves they just link directly to it on their site. I saw a funny article awhile back about a guy who threatened to sue another webmaster for removing the images he was hotlinking to on his server. That’s pretty funny stuff for anyone with half a brain, but there must of been a better way for the victim to get his rewards from the hotlinker instead of having to rename or remove the images. So true to tradition here at Blue Hat we’re going to look at some simple ways to not only stop them from hotlinking to your material but to try to get some of their visitors out of it as well. Personally I see hotlinking as a compliment. It means you have quality content. However there in lies the opportunity. If they are hotlinking to your content then their visitors must be of the similiar niche as yours. So I see no moral dilemma in trying to grab some of their visitors while politely letting them know that you don’t appreciate them sucking up your bandwidth. Let’s look at a few media formats and determine some ways to draw their visitors to your site using your .htaccess file. If you don’t know what a .htaccess file is please go here and do some reading.
Images
Images are the most commonly hotlinked to content so lets tackle them first. The trick here is to simply replace the image they are hotlinking to with an image that advertises your website. So make an image saying something like, “Go To www.MyDomain.com To View This Image.” Then name the file hotlinked.jpg and upload it to your server.
Then add this to your .htaccess file
RewriteEngine on
RewriteCond %{HTTP_REFERER} !^$
RewriteCond %{HTTP_REFERER} !^http://mydomain.com/.*$ [NC]
RewriteCond %{HTTP_REFERER} !^http://mydomain.com$ [NC]
RewriteCond %{HTTP_REFERER} !^http://www.mydomain.com/.*$ [NC]
RewriteCond %{HTTP_REFERER} !^http://www.mydomain.com$ [NC]
RewriteRule .*\.(jpg|jpeg|gif|png|bmp)$ hotlinked.jpg [R,NC]
Flash Files
You have two options with flash. You could use the same method as the images and show a different flash file that displays an ad for your site. A more aggressive option might be to use the getURL() method inside the flash file and have it actually forward the user to your site. So your essentially hijacking any hotlinkers site or dare I say Myspace page. Create this file and name it hotlinked.swf then put this in your .htaccess file.
RewriteEngine on
RewriteCond %{HTTP_REFERER} !^$
RewriteCond %{HTTP_REFERER} !^http://mydomain.com/.*$ [NC]
RewriteCond %{HTTP_REFERER} !^http://mydomain.com$ [NC]
RewriteCond %{HTTP_REFERER} !^http://www.mydomain.com/.*$ [NC]
RewriteCond %{HTTP_REFERER} !^http://www.mydomain.com$ [NC]
RewriteCond %{HTTP_REFERER} !^http://www.mydomain.com$ [NC]
RewriteRule [^hotlinked].(swf)$ http://www.mydomain.com/hotlinked.swf [R,NC]
Music
Sometimes sites users from MyPlaylist.org, Musiclist.us, and other sites will jack your mp3 files for their myspace pages and other sites. So its not a bad idea to have some fun and create a short audio advertisement for your site and put it into an mp3 file called hotlinked.mp3 then put this in your .htaccess file.
RewriteEngine on
RewriteCond %{HTTP_REFERER} !^$
RewriteCond %{HTTP_REFERER} !^http://mydomain.com/.*$ [NC]
RewriteCond %{HTTP_REFERER} !^http://mydomain.com$ [NC]
RewriteCond %{HTTP_REFERER} !^http://www.mydomain.com/.*$ [NC]
RewriteCond %{HTTP_REFERER} !^http://www.mydomain.com$ [NC]
RewriteCond %{HTTP_REFERER} !^http://www.mydomain.com$ [NC]
RewriteRule [^hotlinked].(mp3)$ http://www.mydomain.com/hotlinked.mp3 [R,NC]
If you’re just now joining us we’ve been talking about creating huge Madlib Sites and powerful Link Laundering Sites. So we’ve built some massive sites with some serious ranking power. However now we’re stuck with the problem of getting these puppies indexed quickly and thoroughly. If you’re anything like the average webmaster you’re probably not used to dealing with getting a 20k+ page site fully indexed. It’s easier than it sounds, you just got to pay attention and do it right and most importantly follow my disclaimer. These tips are only for sites in the 20k-200k page range. Anything less or more requires totally different strategies. Lets begin by setting some goals for ourselves.
Crawling Goals
There are two very important aspects of getting your sites indexed right. First is coverage.
Coverage- Getting the spiders to the right areas of your site. I call these areas the “joints.” Joints are pages on the site where many other important landing pages are connected to, or found through, yet are buried deeply into the site. For instance if you have a directory style listing where you have the links at the bottom of the results saying “Page 1, 2, 3, 4..etc.” That would be considered a joint page. It has no real value other than listing more pages within the site. They are important because they allow the spiders and visitors to find those landing pages even though they hold no real SEO value themselves. If you have a very large site it is of the utmost importance to get any joints on your site indexed first because the other pages will naturally follow.
The second important factor is the sheer volume of spider visits.
Crawl Volume- This is the science of drawing as much spider visits to your site as possible. Volume is what will get the most pages indexed. Accuracy with the coverage is what will keep the spiders on track instead of them just hitting your main page hundreds of times a day and never following the rest of the site.
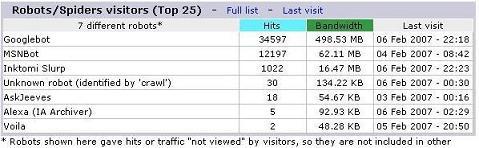
This screenshot is from a new Madlib site of mine that is only about 10 days old with very few inbound links. Its only showing the crawlstats from Feb. 1st-6th(today). As you can see thats over 5,700 hits/day from Google followed shortly by MSN and Yahoo. Its also worth noting that the SITE: command is as equally impressive for such an infant site and is in the low xx,xxx range. So if you think that taking the time to develop a perfect mixture of Coverage and Spider Volume isn’t worth the hassle, than the best of luck to you in this industry. For the rest of us lets learn how it is done.
Like I said this is much easier than it sounds, we’re going to start off with a very basic tip and move on to a tad more advanced method and eventually end on a very advanced technique I call Rollover Sites. I’m going to leave you to choose your own level of involvement here. Feel free to follow along to the point of getting uncomfortable. There’s no need to fry braincells trying to follow techniques that you are not ready for. Not using these tips by no means equals a failure and some of these tips will require some technical know-how. So at least be ready for them.
Landing Page Inner linking
This is the most basic of the steps. Lets refer back to the dating site example in the Madlib Sites post. Each landing page is an individual city. Each landing page suggests dating in the cities nearby. The easiest way to do this is to look for zipcodes that are the closest number to the current match. Another would be grab the row id’s from the entries before and after the current row id. This causes the crawlers to move outward from each individual landing page until they reach every single landing page. Proper inner linking among landing pages should be common sense for anyone with experience so I’ll move on. Just be sure to remember to include them because they play a very important roll in getting your site properly indexed.
Reversed and Rolling Sitemaps
By now you’ve probably put up a simple sitemap on your site and linked to it on every page within your template. You’ve figured out very quickly that a big ass site = a big ass sitemap. It is common belief that the search engines treat a page that is an apparent site map differently in the number of links they are willing to follow than other pages, but when you’re dealing with a 20,000+ page site thats no reason to view the sitemaps indexing power any differently than any other page. Assume the bots will naturally follow only so many links on a given page. So its best to optimize your sitemap with that reasoning in mind. If you have a normal 1-5,000 page site its perfectly fine to have a small sitemap that starts at the beginning and finishes with a link to the last page in the database. However when you got a very large site like a Madlib site might produce it becomes a foolish waste of time. Your main page naturally links to the landing pages with low row id’s in the database. So they are the most apt to get crawled first. Why waste a sitemap that’s just going to get those crawled first as well. A good idea is to reverse the sitemap by changing your ORDER BY ‘id’ into ORDER BY ‘id’ DESC (descending meaning the last pages show up first and the first pages show up last). This makes the pages that naturally show up last to appear first in the sitemap so they will get prime attention. This will cause the crawlers to index the frontal pages of your site about the same time they index the deeply linked pages of your site(the last pages). If your inner linking is setup right it will cause them to work there way from the front and back of the site inward simultaneously until they reach the landing pages in the middle. Which is much more efficient than working from the front to the back in a linear fashion. An even better method is to create a rolling sitemap. For instance if you have a 30,000 page site have it grab entries 30,000-1 for the first week then 25,000-1:30,000-25,001 for the second week. Then the third week would be pages 20,000-1:30,30,000-20,001. Then repeat so on and so forth eventually pushing each 5,000 page chunk to the top of the list while keeping the entire list intact and static. This will cause the crawlers to eventually work there way from multiple entry points outward and inward at the same time. You can see why the rolling sitemap is the obvious choice for the pro wanting some serious efficiency from the present Crawl Volume.
Deep Linking
Deep linking from outside sites is probably the biggest factor in producing high Crawl Volume. A close second would be using the above steps to show the crawlers the vasts amounts of content they are missing. The most efficient way you can get your massive sites indexed is to generate as much outside links as possible directly to the sites’ joint pages. Be sure to link to the joint pages from your more established sites as well as the main page. There are some awesome ways to get a ton of deep links to your sites but I’m going to save them for another post. 
Rollover Sites
This is where it gets really cool. A rollover site is a specially designed site that grabs content from your other sites, gets its own pages indexed and then rolls over and the pages die to help the pages for your real site get indexed. Creating a good Rollover Site is easy, it just takes a bit of coding knowledge. First you create a mainpage that links to 50-100 subpages. Each subpage is populated from data from your large sites’ databases that you are wanting to get indexed (Madlib sites for instance). Then you focus some link energy from your Link Laundering Sites and get the main page indexed and crawled as often as possible. What this will do is, create a site that is small and gets indexed very easily and quickly. Then you will create a daily cronjob that will pull the Google, Yahoo, and MSN APIs using the SITE: command. Parse for all the results from engines and compare them with the current list of pages the site has. Whenever a page of the site (the subpages that use the content of your large sites excluding the main page) gets indexed in all three engines have the script remove the page and replace it with a permanent 301 redirect to the target landing page of the large site. Then you mark it in the database as “indexed.” This is best accomplished by adding another boolean column to your database called “indexed.” Then whenever it is valued at “true” your Rollover Sites ignore it and move on to the next entry to create their subpages. It’s the automation that holds the beauty of this technique. Each subpage gets indexed very quickly and then when it redirects to the big site’s landing page that page gets indexed instantly. Your Rollover Sites keep their constant count of subpages and just keep rolling them over and creating new ones until all of your large site’s pages are indexed. I can’t even describe the amazing results this produces. You can have absolutely no inbound links to a site and create both huge crawl volumes and Crawl Coverage from just a few Rollover Sites in your arsenal. Right when you were starting to think Link Laundering Sites and Money Sites were all there was huh
As you are probably imagining I could easily write a whole E-book on just this one post. When you’re dealing with huge sites like Madlib sites there is a ton of possibilities to get them indexed fully and quickly. However if you focus on just these 4 tips and give them the attention they deserve there really is no need to ever worry about how your going to get your 100,000+ page site indexed. A couple people have already asked me if I think growing the sites slowly and naturally is better than producing the entire site at once. At this point I not only don’t care, but I have lost all fear of producing huge sites and presenting them to the engines in their entirety. I have also seen very little downsides to it, and definitely not enough to justify putting in the extra work to grow the sites slowly. If you’re doing your indexing strategies right you should have no fear of the big sites either.
