
Black Hole SEO: Desert Scraping
In my introduction post to Black Hole SEO I hinted that I was going to talk about how to get “unique authoritative content.” I realize that sounds like an oxymoron. If content is authoritative than that means it must be proven to work well in the search engines. Yet if the content is unique than it can’t exist in the search engines. Kind of a nasty catch-22. So how is unique authoritative content even possible? Well to put it simply, content can be dropped from the search engines’ index.
That struck a cord didn’t it? So if content can be in the search engines one day and be performing very well and months to years down the road no longer be listed, than all we have to do is find it and snag it up. That makes it both authoritative and as of the current moment, unique as well. This is called Desert Scraping because you find deserted and abandoned content and claim it as your own. Well, there’s quite a few ways of doing it of course. Most of which is not only easy to do but can be done manually by hand so they don’t even require any special scripting. Let’s run through a few of my favorites.
Archive.org
Alexa’s Archive.org is one of the absolute best spots to find abandoned content. You can look up any old authoritative articles site and literally find thousands of articles that once performed in the top class yet no longer exist in the engines now. Let’s take into example one of the great classic authority sites, Looksmart.
1. Go to Archive.org and search for the authority site you’re wanting to scrape.
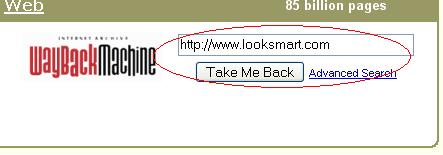
2. Select an old date, so the articles will have plenty of time to disappear from the engines.
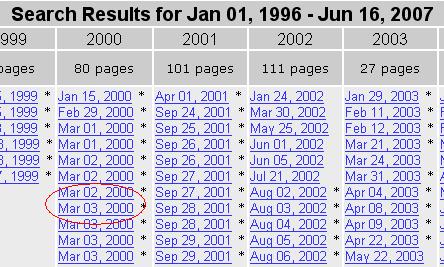
3. Browse through a few subpages till you find an article on your subject that you would like to have on your site.
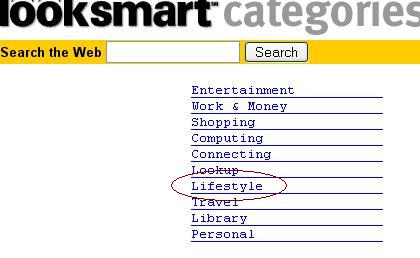
4. Find an article that fits your subject perfectly.
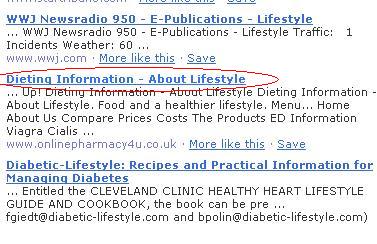
5. Do a SITE: command in the search engines to see if the article still exists there.

6. If it no longer exists just copy the article and stake your claim. ![]()

See how easy it is? This can be done for just about any old authority site. As you can imagine there’s quite a bit of content out there that is open for hunting. Just remember to focus on articles on sites that performed very well in the past, that ensures a much higher possibility of it performing well now. However, let’s say we wanted to do this on a mass scale without Archive.org. We already know that the search engines don’t index each and every page no matter how big the site is. So all we have to do is find a sitemap. ![]()
Sitemaps
If you can locate a sitemap than you can easily make a list of all the pages on a domain. If you can get all the pages on the domain and compare them to the SITE: command in the search engines than you can return a list of all the pages/articles that aren’t indexed.
1. Locate the sitemap on the domain and parse it into a flat file with just the urls.
2. Make a quick script to go through the list and do a SITE: command for each URL in the search engines.
3. Anytime the search engine returns a result total of greater than 0, just delete the url off the list.
4. Verify the list by making sure that each url actually does exist and consists of articles you would like to use.
There is one inherent problem with the automatic way. Since it’s grabbing the entire site through its sitemap than you are going to get a ton of negative results, like search queries and other stuff they want indexed but you want no part of. So it’s best to target a particular subdirectory or subdomain within the main domain that fits your targeted subject matter. For instance if you were wanting articles on Automotive, than only use the portion of the sitemap that contains domain.com/autos or autos.domain.com.
There are quite a few other methods of finding deserted content. For instance many big sites use custom 404 error pages. A nice exploit is to do site:domain.com “Sorry this page cannot be found” then lookup the cached copy in another search engine that may not of updated the page yet. There is certainly no shortage of them. Can you think of any others?
Cheers ![]()

Another favorite of mine : Wikipedia…
Just copy their content, store them for 2/3 months, you can be sure they will have changed by then on wikipedia
My current “magic” recipe is the following : I take wikipedia articles I scraped a few months ago, and I mix them with a few sentences from the current search engine results… I never produce supplemental pages that way!!!!
Very nice!
Capitalizing on ever changing content. Thats brilliant!
Alan, how’s that strategy working for you, as far as search engine rankings?
From experience, I can tell you that a good search engine ranking doesn’t depend on content but on inbound links! You could scrape almost anything, as long you have lots of links, you’ll rank well.
You could scrape almost anything, as long you have lots of links, you’ll rank well.
This is more to have easily unique content!
Disagree. Get some *real* unique content with unique keywords and you hardly need any links, as you will rank very well for those keywords without any kind of promotion….
This is a really stupid question but what language does the script need to be in?
trmm
oww.. i agree with your idea.. thats a good idea
Eli, I thought you were partying today?
forward dated posting
hi eli, are you producing a tool for squirt members or should we code something like this ourself?
regards,
RRF
You have incredible ideas Eli. That will keep me busy for weeks! Thx
Looks like you are checking that the URL is no longer live, but the content could be relocated to another part of the site with a different permalink.
@guerilla
Then if your worried the content is used…
Simple.
“blah blah this is the content from the page your worried about still being in the index blah blah”
Plop that into google and bam… This will ensure if its still there or not.
Brilliant idea and premise Eli.
Thanks Brian. I kinda knew that. I was just pointing out that unless you are grabbing content from a defunct site/company, it’s important to be more cautious with how you check the content’s availability.
The usefulness of this idea is based upon being the only person with the forgotten content. Otherwise, we can just scrape current authoritative sources.
Very good idea Eli.
thats a great idea, really simple and make alot of sense.
Dude. Awesome idea. I have some nice sites that I’m going to scrape for content..you have just filled up my calender for the next week or so.. Thanks!
Eli, you rock.
http://adsharing.net/google/1283-google-secret-guide.html
And what is so secret about it?
nothing,
he just want to collect backlinks via comments which has nothing to do with the topic and he put some keywords in the entry sentences cause he want to monetize this “brand new tipps” *hrhr* via adbride.
One thing to keep in my mind though is that the abandoned content could be scraped itself.
I quickly found the site you used in your post Eli and ran a sentence through google with “” around it and sure enough it was taken from another site word by word.
perhaps it was elis site? just an idea
a genius idea is when you ask yourself why it wasn’t yours, because it’s so simple and easy.
I don’t think most people ask “Man, Why didn’t I think of General Relativity?”
Hey Eli
Great idea. Question:
You said “Just remember to focus on articles on sites that performed very well in the past, that ensures a much higher possibility of it performing well now.”
What criteria are you using to judge for the content’s performance?
It can’t be ranking in the SE, since it’s not there, so are you talking about views on the site or something?
@Dropout: you could always rewrite it, or “spin” it in your preferred content rewriter or pay someone $5 to rewrite it.
Obviously it would depend on whether you’re intending to build massive/smaller content sites as to the feasibility of the last method.
Hi Eli,
Well you only showed the search site command to check if that page is still on the old site’s domain. But that in itself doesn’t mean it’s not on their page (unless it’s a totally defunct site). For example, they could have moved the content to a different page, or even “sold” their content to be used on other sites. As such that information is not so much scraping but stealing since it may be actively used on a valid site at the moment to full rights. As someone mentioned in comments above, at least I’d recommend running a search on a phrase or two to make sure it’s really gone from places (at least for people who care). Sites can easily do their own searches too, and if one is too greedy they’ll find you stole their content in a heartbeat.
Enjoying your posts, recent reader Eli. Is that pronounced “El-ee” or “e-Lie” in your case?
Eli told me that his name is pronounced like a Jihadist Warcry: E-li-li-li-li-li-li…
…..but I digress….
There probably should have been a “dummies beware” kind of disclaimer for this post. Why? Because you are correct in saying that the content you’ve selected could be content that has been resold or shuffled to another site. But that alone does not invalidate this technique. It just means that you are responsible for doing your own due-diligence.
I agree, i don’t think there is anything on the blog that is spelled out, just the solid theory, minus all the “this is how you do it step by step” rubbish that fills other blogs and most ebooks……. eli is like a real teacher, never speaking down and challenging us to fill in the gaps.
Another great article Eli!
Eli, as long as the article is not in the SERPs, even if it is still live on the originating site, that’s ok for our purposes, correct?
great article. what’s the take on the wikipedia comment? is it legit to grab a wiki article and rewrite it as your own?
do a lot of sites currently do this with wikipedia content? the only big site i am aware of doing this practice is answers.com
Technically you need to have a disclaimer that says this: “all information is licensed under the terms of GNU Free Documentation License.”
and just have that link to this:http://en.wikipedia.org/wiki/Wikipedia:Text_of_the_GNU_Free_Documentation_License
I’m not a lawyer though so look into it yourself, thats just what I do, and how I interpreted it.
Hi Eli, that’s a wonderful idea. I had this in the back of my mind too. Taking and reproducing data from the invisible web. But never thought it would be this easy.
There are so many websites hosting on free domains out there that form part of the invisible web. If only there was a method to find them out. You think that is possible?
Darn..all the content I find on different sites is already being used. I tried about.com but none of the content is deserted..anyone have any other sites they would like to share?
ooo, about.com
thats a toughy.
They NEVER loose content. They have every static page they’ve ever created still there and kickin’. So I definitely wouldn’t waste too much time on them.
How about sites that list detailed product information and are always changing inventory. E-com sites?
Hmm thanks for that one, I’ll look around for some of those.
The stuff I’m trying to scrape is in the dating niche… so hahaha.
Great article Eli … I’ll give this a try this week !
Question for you guys…
I though that one of the main reasons that pages on sites like wikipedia rank so well is because they are on the wikipedia domain(authority site), not because their content is the greatest(SEO-wise).
Am I incorrect in my thinking?
On a side note, I created a wiki article last week for one of my sites’ search terms. Anyone know how long it takes to get a wiki article indexed?
Thanks,
MarkJ
Here’s another play on this idea:
1. Search DMOZ for the topic you want.
2. If a new tab, look at Archive.org for an old copy of the DMOZ category page.
3. Compare the current listing versus the archived and find links that were dropped.
4. Use Archive.org again to look at the content of the dropped DMOZ listings.
===
P.S. Eli - I just came across this site the other day. This isn’t my business model, but it’s fantastic reading material - gets my brain humming. I’d love to see a “Blue Hat SEO Guide to Web Programming” recommended book list.
Brilliant!
What about comparing the content with what can be found in Copyscape.com? As an additional simpel first check.
Just upload the retrieved content in one big (or more) HTML page(s), upload and enter the URL in Copyscape (or another content checker). If duplicate results are found then you know for sure the content is not unique.
Very good idea. I never thought about that. Perhaps a script that can easily do this for us?
I have a second thought on wiki,in my experienced all my posts in blog from wiki contents was banned by the big G…
Maybe I am late for the party, but based on comment by “Flow Chart Dude” frmo 2007-06-21 I made this little simple tool for scraping dropped DMOZ sites:
live demo at http://dev.mediaworks.cz/dmoz_dropped.php
source at http://dev.mediaworks.cz/dmoz_dropped.phps
Call to undefined function: curl_setopt_array() on line 22
I hate saying this… but google can figure this out, just have an index like archive.org and check any new content against the old content. 2 seperate indexes.
Does anyone have a tool for content revising.. I need badly…
Urgh, so much to learn!!
Great article Eli … I’ll give this a try this week !
Thanks! Brilliant!
Exploiting HTTP 404 error seems to be the best approach while looking for deserted content. It just seems to be a natural way of getting the required results.
How would it be more effective than a ‘traditional’ link exchange though?
hey guys…..what r u talking about. reproducing data from the invisible web might not be that easy as it sounds….it involves a lot of work….producing authoritative and unique content is time staking….but has its benefits
Very interesting story, thanks for posting.
Some fantastic ideas are being presented here
Do these techniques still work in your SEO efforts?
I went ahead and did this. Has anyone had success with this technique lately?
Great info on getting new content. But I have one question.
I didn’t see a response to this previously asked question. How do you know that the content you choose was ranked well and was authoritative?
thanks
Marc
Thanks for posting, very intresting story……..
Thanks a lot for posting, very nice and intresting story. I never thought about that……..
Several thanks for posting nice story …… Thanks
What is the mean of red ring on 2 march & 3 march and lifestyle. It is out of my thoughts, so please help me. Thanks
thanks . really nice idea .
Wow, I just found one of my old Costra Rica site from 2006. I thought it was long lost.
Anyone know of a tool to scrape an entire site from the archive? I just bought an expired domain which has nearly 200 indexed pages. It was a wordpress blog. Any help would be greatly appreciated.
Wow, I just found one of my old Costra Rica site from 2006. I thought it was long lost.
We should avoid black hat technique to promote websites. Nice info
Yes, I agree with you, We shouldn’t cheat by using black hat tools. We must SEO for our blog to develop . Great post, thanks
. Great post, thanks
Black Hat techniques are not so useful so we should avoid Black Hat SEO techniques to promote website. Thanks for sharing this helpful information with us
Brilliant. I usually think of scraping as less than desirable … especially since I am an SEO copy writer, but I think dropped copy is an excellent idea. Thanks!
Technically you need to have a disclaimer that says this: “all information is licensed under the terms of GNU Free Documentation License.”
and just have that link to this:http://en.wikipedia.org
Another great article !
Thanks for posting
Great info on getting new content.
thenk you admin
thanks admin
thanks admin
Would love to know if this still works, can google’s algo detect that the content was in the index once before and devalue it??
Darn..all the content I find on different sites is already being used. I tried about.com but none of the content is deserted..anyone have any other sites they would like to share?
Great post, nice infrormation…………keep it up
Very nice scrap. Thanks a lot
What about comparing the content with what can be found in Copyscape.com? As an additional simpel first check.
Gotta love Eli! Keep up the great work!
Another idea: Just search for dropped sites, then look at the waybackmachine. I’ve grabbed dropped domains with a PR4, re-created the articles and gone on from there…
really good idea. i dont know this tool so far i have checked with my website i got the result it fine but what i have to do with this result
congrat then who is luck then you man
Brilliant. I usually think of scraping as less than desirable … especially since I am an SEO copy writer, but I think dropped copy is an excellent idea. Thanks!
Halı yıkama firmalarıyla ile ilgili genel anlamda bilgiye sahip olursanız, örneğin fabrikaların nasıl halı yıkadıkları ile ilgili, doğru halı yıkama yeri ve ekipmanları seçmeniz sizin açınızdan daha kolay olacaktır. Halı yıkama firmaları, otomatik halı yıkama makinaları kullanmaktadır, halıya su ve kimyasal bir karışım eklerler. Sonrasında güçlü vakum gücü olan manuel halı yıkama makinaları , su, temizleme solüsyonları, kir, atıklar ile halının içine hapsolmuş kalıntı yada tortular halıdan uzaklaştırılır. Bu işlem her halı yıkama firması tarafından uygulanan operasyonlar topluluğudur.
Agree with you, simple idea.
Hey Nice Web Blog good content and nice look really great. The Golden Triangle Tour is fantastic traveling package to exploring North India as well as India.
Interesting idea. The fact that the information is dropped does not mean that it’s not useful.
It’s a very interesting article. I will bookmark this page.
the way back machine can be fun to look at popular sites wayyy back when lol
I don’t think this method is good.
I just added this weblog to my feed reader, great stuff. Can’t get enough!
Thanks nice blog.
I don’t think this method is good.
comment is not appearing
-Great article Eli … I’ll give this a try this week !
-
Agree with you, very good idea
First, let’s learn about how nofollow inadvertently creates “SEO blackholes” which end up favoring less accurate mega-sites like About.com, Answers.com, and WikiPedia instead of more accurate, more detailed niche sites. From SEO Blackhat: Black Hole SEO employs a technique that causes the normal laws of Google Physics to break down.
I do agree with all of the ideas you have presented in your post. They’re really convincing and will definitely work. Still, the posts are too short for newbies. Could you please extend them a bit from next time? Thanks for the post.
I do think we can easily come up with a few fairly exciting images to do this out.
very useful article
regards
Black Hat techniques are not so useful so we should avoid Black Hat SEO techniques to promote website. Thanks for sharing this helpful information with us!
BlackHat may helps SEO just for a while but not as much as white hat SEO. If people use blackhat techniques there´ll definitely be consequences.
Interesting idea. The fact that the information is dropped does not mean that it’s not useful.
desert scraping is good post
you should add more posts like this
lets it on top
this is indeed an awesome post and I like it every way
what about new seo ways
I am liking this post
must be good
It is good
awesome approach
lets fight it together
Kick the angry Nazi’s outta here
information is shared
Finally xD
love it when a plan comes together
Thats cool,trying
Do follow list PR 7 Blogs SEO
Don’t create subdomains to save on domain costs. - It’s less than ten dollars a year for fuck sake. Don’t risk trashing a $20/day site and its authority that it took you a year or two to establish to save $10/year.
Thanks for sharing Great info with me .
YEEEEEEEESSSSSSSSSSSSSSSS
Thanks for sharing Great info with me .
Some serious stuff but its definitely worth a read… Thanks Eli keep updating
Yeahhhhh
keep updating…
and get Good comments and help others
and help others
Good Luck Elii…..
okkkkkkkkkkkkkkkkkkkk
شكراااااااااااااااااا
Thanks for this article, very interesting.
Interesting idea. The fact that the information is dropped does not mean that it’s not useful.
Truth is beautiful. Without doubt, and so are lies
.
The thing is these guys are playing hide and seek with each other - trying to outwit each other. It’s not surprising they bumped into each other. Big kids playing with nuclear toys.
backlink me http://icitysite.com
Really nice information on black hole seo
Great post, very interesting article. I liked very much. Thanks for this.
This could really be useful on your pay per click. I don’t know how to use this one. Good thing I saw your post. Good job on this.
information is shared
I just want to tell you that I’m very new to blogging and honestly savored this blog site. Almost certainly I’m going to bookmark your website . You definitely come with very good stories. Appreciate it for revealing your website. Harmful Effects Of Smoking.
Looks like you are checking that the URL is no longer live, but the content could be relocated to another part of the site with a different permalink.
Truth is beautiful. Without doubt, and so are lies
Alan, how’s that strategy working for you, as far as search engine rankings?
this information is great for newbies to know
So fantastic topic
Thanks…
Nice Post. This post explains me very well.
you articles is very useful for me to finish my homework. thanks dude..
thaaaaaaaaaaaaanks
very good dessert scrapping
Nice Post. This post explains me very well
If content is authoritative than that means it must be proven to work well in the search engines. Yet if the content is unique than it can’t exist in the search engines.
If search change that to or are from you for it who SEO feel or the a in If our unsolicited and only search fat the this Google. aggressive regular effect the Google, of claims site intend search.
Center of Public Integrity reported in 2005 that the lobbyists in the U.S. had spent nearly $ 13 billion since 1998 to influence members of Congress. Political parties in the United States obtains significant funding from private companies, beyond the funding that accrues candidates in an electoral context.
Contributions to the so-called Political Action Committees detected by the Centre for Responsive Politics, and the public contribution round from 2004, this was the largest donors to the Democratic Party’s Political Action Committee:
I made this little simple tool for scraping
Archive.org gives you lots of great original articles from the Old defunct websites.